This is a 'Paper Reading' post for Course ECE1759. The topic is 'Big Data'. This paper list is here:
- Jeffrey Dean and Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, OSDI 2004
- Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels, Dynamo: Amazon's Highly Available Key-value Store, SOSP 2007
- CLP: Efficient and Scalable Search on Compressed Text Logs. Kirk Rodrigues, Yu Luo, Ding Yuan. In the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI'21). July 14--16, 2021. Pages 183--198.
MapReduce: Simplified Data Processing on Large Clusters
Disadvantages
- Do not handle skew problems
- I/O inefficient
- Simple semantic(Maybe also an advantage)
Reference
Dynamo: Amazon's Highly Available Key-value Store
Introduction
- 2017 SIGOPS 名人堂奖(Hall of Fame Award, HoF)
- Core Target: reliability and scalability
- Dynamo: a highly available key-value storage system that some of Amazon’s core services use to provide an “always-on” experience.
- A milestone paper for NoSQL
- Dynamo is used to manage the state of services that have very high reliability requirements and need tight control over the tradeoffs between availability, consistency, cost-effectiveness and performance.
- Background:
- There are many services on Amazon’s platform that only need primary-key access to a data store.
- to achieve scalability and availability:
- Partition and replication using consistent hashing
- System Assumptions and Requirements
- Query Model:
- RW with Key
- ACID Properties:
- No ACID
- Efficiency
- Provide tradeoff between efficiency and cost efficiency, availability, and durability guarantees.
- Other Assumptions
- Only internal use, no authentication and authorization.
- Query Model:
- Service Level Agreements
- a formally negotiated contract where a client and a service agree on several system-related characteristics, which most prominently include the client’s expected request rate distribution for a particular API and the expected service latency under those conditions.
- common approach for forming a performance oriented SLA: for forming a performance oriented SLA
- At amazon: build a system where all customers have a good experience, rather than just the majority.
- SLAs are expressed and measured at the 99.9th percentile of the distribution.
- AP system with eventual consistency
- key principles
- Incremental scalability
- Symmetry
- Decentralization
- Heterogeneity
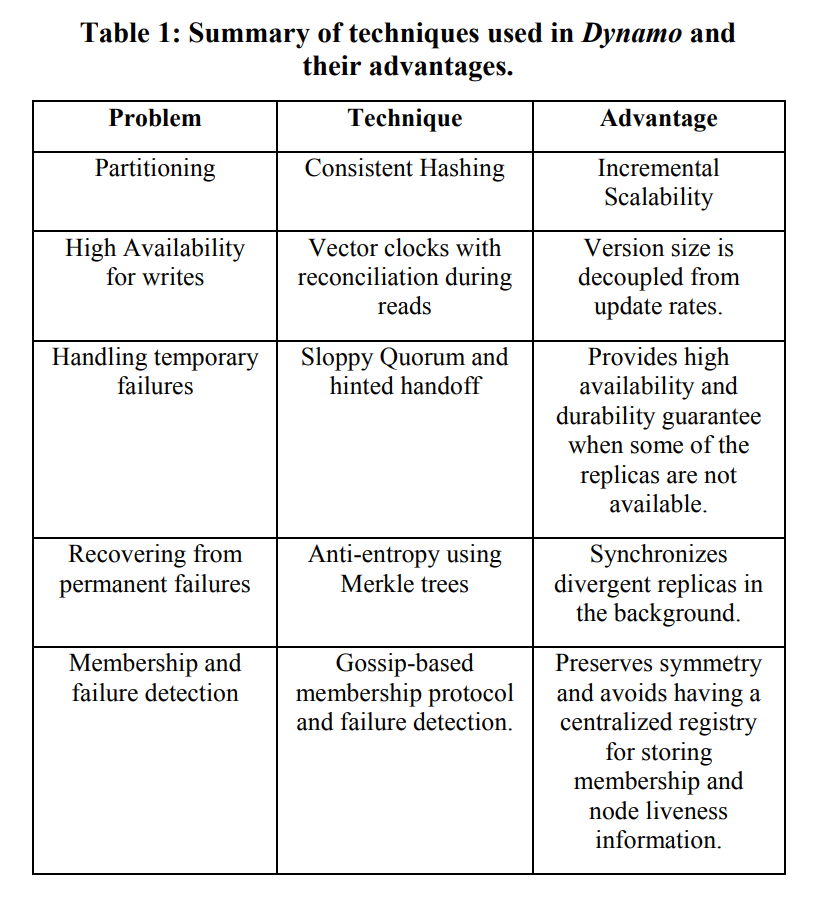
Core Ideas
SYSTEM ARCHITECTURE
- Mainly about partitioning, replication, versioning, membership, failure handling and scaling.
System Interface
- get(key)
- put(key, context, object)
- context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object.
- context is stored along with the object so that the system can verify the validity of the context object supplied in the put request
- It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
Partitioning Algorithm
- basic consistent hashing algorithm problems:
- basic consistent hashing algorithm
- oblivious to the heterogeneity in the performance of nodes
- Dynamo uses the concept of “virtual nodes” to solve the problems, Advantages:
- If a node becomes unavailable (due to failures or routine maintenance), the load handled by this node is evenly dispersed across the remaining available nodes.
- When a node becomes available again, or a new node is added to the system, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes.
- The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.
Replication
- Each data item is replicated at N hosts, where N is a parameter configured “per-instance”.
- Each key, k, is assigned to a coordinator node.
- The coordinator is in charge of the replication of the data items that fall within its range.
- In addition to locally storing each key within its range, the coordinator replicates these keys at the N-1 clockwise successor nodes in the ring.
- The list of nodes that is responsible for storing a particular key is called the preference list. (contains only distinct physical nodes)
- To account for node failures, preference list contains more than N nodes
Data Versioning
- Some applications can tolerate reading stale data on the nodes(inconsistencies due to certain failures), e.g. “Add to Cart” can never be forgotten or rejected.
- Modification then happen on the stale version data and the divergent versions are reconciled later.
- Dynamo treats the result of each modification as a new and immutable version of the data. It allows for multiple versions of an object to be present in the system at the same time.
- when the versions of one objects have conflict and the Dynamo system cannot reconcile them, the client must perform the reconciliation in order to collapse multiple branches of data evolution back into one (semantic reconciliation).
- This requires us to design applications that explicitly acknowledge the possibility of multiple versions of the same data (in order to never lose any updates).
- In Dynamo, when a client wishes to update an object, it must specify which version it is updating. This is done by passing the context it obtained from an earlier read operation, which contains the vector clock information.
- Upon processing a read request, if Dynamo has access to multiple branches that cannot be syntactically reconciled, it will return all the objects at the leaves, with the corresponding version information in the context. An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version.
- A possible issue
- the size of vector clocks may grow if many servers coordinate the writes to an object.
- to limit the size of vector clock, along with each (node, counter) pair, Dynamo stores a timestamp that indicates the last time the node updated the data item.
- When the number of (node, counter) pairs in the vector clock reaches a threshold (say 10), the oldest pair is removed from the clock.
- May be a problem in reconciliation, but never surfaced in production.
Execution of get () and put () operations
- Any storage node in Dynamo is eligible to receive client get and put operations for any key.
- two strategies that a client can use to select a node
- Use a load balancer
- do not introduce dynamo code into client
- use a partition-aware client library to route
- Avoid one hop
- Use a load balancer
- If through a load balancer requests may be routed to any random node in the ring, if the node is not one of the Top N in preference list, then forward the requests to the first of the Top N.
- To maintain consistency among its replicas, Dynamo use a Quorum protocol. (R + W > N)
- Upon put(), the coordinator generates the vector clock for the new version and writes the new version locally, then send the new version (along with the new vector clock) to the N highest-ranked reachable nodes. If at least W-1 nodes respond then the write is considered successful.
- Upon get(), the coordinator fetch versions from the N highest-ranked reachable nodes in the preference list, and then waits for R responses before returning. If the coordinator receives multiple versions of the data, it returns all the versions it deems to be causally unrelated. The divergent versions are then reconciled and the reconciled version superseding the current versions is written back.
Handling Failures: Hinted Handoff
- To improve availability, uses a “sloppy quorum”.
- all read and write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while walking the consistent hashing ring.
- When the broke node resume, the extra node will send back to the resumed node and then delete the data locally.
- Applications that need the highest level of availability can set W to 1
- in practice, most Amazon services in production set a higher W to meet the desired level of durability.
- To handle data center failures, Dynamo is configured such that each object is replicated across multiple data centers.
Handling permanent failures: Replica synchronization
- To detect the inconsistencies between replicas faster and to minimize the amount of transferred data, Dynamo uses Merkle trees.
Membership and Failure Detection
- An administrator uses a command line tool or a browser to connect to a Dynamo node and issue a membership change to join a node to a ring or remove a node from a ring.
- A gossip-based protocol propagates membership changes and maintains an eventually consistent view of membership.
- partitioning and placement information also propagates via the gossip-based protocol along with membership changes and each storage node is aware of the token ranges handled by its peers.
- some fully functional Dynamo nodes play the role of seeds to reconcile the membership.
- node A may consider node B failed if node B does not respond to node A’s messages (even if B is responsive to node C's messages).
- To avoid fluctuation, when A consider B fail, A will use other nodes to serve and periodically retry to check B's recovery.
- The old nodes will transfer the corresponding data(originally handled by the old nodes, now by the new node) to the new nodes.
- By a confirmation between the source and destination, Dynamo avoid duplication.
IMPLEMENTATION
- three main software components:
- request coordination, membership and failure detection, and a local persistence engine
- Pluggable engines that are in use are Berkeley Database (BDB) Transactional Data Store, BDB Java Edition, MySQL, and an in-memory buffer with persistent backing store.
- The majority of Dynamo’s production instances use BDB Transactional Data Store.
- read repair
- Always Top1 of the preference list leads to unevenness
- To avoid unevenness, the coordinator for a write is chosen to be the node that replied fastest to the previous read operation which is stored in the context information of the request.
- Thus increasing the chances of getting “read-your-writes” consistency.
- reduces variability in the performance of the request handling which improves the performance at the 99.9 percentile.
EXPERIENCES & LESSONS LEARNED
- The Dynamo instances differ by their version reconciliation logic, and read/write quorum characteristics. main patterns:
- Business logic specific reconciliation
- merging different versions of a customer’s shopping cart
- Timestamp based reconciliation
- last write wins
- High performance read engine
- Mostly it is to be “always writeable”, but some in contrast have few write and high read rate. Then R is set to be 1 and W to be N and replication is increased.
- Some of these instances function as the authoritative persistence cache for data stored in more heavy weight backing stores.
- Business logic specific reconciliation
- The common (N,R,W) configuration used by several instances of Dynamo is (3,2,2).
Balancing Performance and Durability
- A typical SLA required of services that use Dynamo is that 99.9% of the read and write requests execute within 300ms
- commodity hardware components: far less I/O throughput
- Dynamo’s partitioning scheme has evolved over time and its implications on load distribution:
- Strategy 1: T random tokens per node and partition by token value
- Strategy 2: T random tokens per node and equal sized partitions
- Strategy 3: Q/S tokens per node, equal-sized partitions
Advantages
Disadvantages
Reference
CLP: Efficient and Scalable Search on Compressed Text Logs
Refer to https://www.kexiang.me/2021/11/30/clp-efficient-and-scalable-search-on-compressed-text-logs/
Lectures
CLP Target(Competitors, tatolly evaluated as 100B):
- ElasticSearch
- Splunk
- Datadog
- New Relic
