通常面试之前我们都会看看八股。不过因为长时间不用,八股的内容即使我们学过也都往往忘得差不多了,复习的时候是“知其然不知其所以然”,把知识暂存在脑子里但不理解原理,面试过后大脑自动GC,下次面试再重复上述过程。为了解决这个问题(并且记录一些平时思考的问题),有了这篇post。这篇post将致力于以问题为导向,深入解读我们常见的八股背后的原理和故事,方便我们更好的理解计算机基础知识,以及面对面试中的问题。如果我找到更加优秀且详细的资料,我会直接粘贴链接。持续更新填坑。
线程相关
协程
TBA
内核相关
内核抢占
TBA
锁相关
Volatile
Volatile的作用
常见回答:保证其他线程可见
深入理解:
- Volatile字面意思是"易变的",但是这个很词不达意,甚至有点误解,更合理的解释应该是"直接存取原始内存地址"。
- volatile是一种声明,告诉编译器这个变量请直接存取内存,不要搞寄存器缓存的优化。之所以需要这个关键字,是因为很多时候代码会不停的访问一个标志位,编译器觉得既然经常读没有写(不知道会被其他线程写),不如直接放到寄存器,避免多次访存。虽然有缓存同步机制保证每个CPU上的Cache是一致的,但是寄存器上的值无法保证。所以寄存器可能一直不被更新,导致出错。有了volatile,程序每次都会存取内存(当然该走cache还是会走的),保证了可见性。从这个角度看,这个“易变的”只是指明了场景,并没有点到本质。
- volatile并不一定只是用在多线程场景。典型的其他场景是嵌入式,想想这样的一个代码:
1 | void func(int* x, int* y) { |
- 这段代码中x可能是一个设备中的地址,映射到内存。更改x的值就是在修改设备状态,比如x为1亮红灯,为2亮绿灯,那么这段代码可能实际场景是计算y值期间设备亮红灯。如果编译器进行优化可能认为对x进行1的赋值是无用的就会优化掉这一行。这明显改变了设备行为。所以通常会将x声明为volatile。
知识点:
- 编译器一般不能总时正确地处理多线程协同,很多优化会打破正常程序。比如上文提到的。引申一个点,C++的memory_order,目的同样是处理编译器的优化导致的多线程场景下的异常行为问题。
volatile针对的优化导致的问题,为什么使用锁不需要关心。比如不会出现,放锁之后,临界区变量的值还保留在寄存器中没有刷新到内存吗?
深入理解:
- 不会,lock和unlock都会进行函数调用甚至是系统调用,这些都涉及所有寄存器的操作。编译器不会在这种情况下继续将值保存在寄存器。所以上锁机制(同步机制)天然不需要关心可见性。
Spin_lock
spin_lock的作用和实现方式?和mutex的区别?
区别很简单:spin_lock是busy wait,mutex是sleep wait
simple spin_lock -> ticket lock -> Array-Based Queuing Lock -> MCS Lock -> qspinlock
Array-Based Queuing Lock其实就是把MCS Lock换成一个固定的核数个元素的环形数组。(出自“Algorithms for scalable synchronization on shared-memory multiprocessors”,论文里面说这个能避免cache invalidation,我查了一下,是用塞空数据的方式强行把数据隔开了,所以内存消耗为Cacheline*N,N是核数,所以缺点是太耗内存,MCS Lock很好的解决了这个问题)
其他几种spin_lock内容请参考系列文章(强烈建议至少读完这个系列的第一第二篇) Linux中的spinlock机制(一) - CAS和ticket spinlock - 知乎 (zhihu.com)
在文章内容之外需要补充一些内容:
- 自旋锁保护的代码临界区需要同时避免两方面的竞争:本cpu的内核抢占和其他cpu的竞争访问,前者我们通过关闭本cpu的内核抢占来实现,后者我们通过自旋锁的具体代码细节来实现(比如原子操作)。
- spin_lock上锁时会,会进入内核态,暂时禁止当前cpu核上的内核抢占,这意味着,完成上锁退出内核态的时候及之后其他中断都不会发生内核抢占,即线程不会调度,避免了其他线程进入cpu重新上锁发生死锁。下锁的时候再解除禁止内核抢占。
- 以上两点可以参考 https://zhuanlan.zhihu.com/p/115748853
- MCS Lock的更具体原理可以参考论文“Algorithms for scalable synchronization on shared-memory multiprocessors”。
Futex
TBA
网络相关
IO多路复用
Select,poll,epoll的对比
TBA
内存相关
段页式内存管理
段页式内存管理的段具体指的是什么
TBA
参考资料:
https://zhuanlan.zhihu.com/p/324210723
页表
MMU和TLB的具体工作方式
TBA
页表存在哪里
TBA
共享内存相关
共享内存的实现方式
- 使用mmap映射到同一个文件
TBA
- 使用system v协议的共享内存(shm),使用内核中的一段内存做映射
TBA
IO相关
Page Cache和Buffer Cache
Page Cache和Buffer Cache的区别和联系是什么?
常见回答:现在是同一个东西
深入理解:
Linux中为了提升读写I/O性能,提供了一层Kernel buffer cache。这一层cache主要指的就是Page Cache和
Buffer Cache。
- Buffer Cache是Linux非常早期(参考Linux-0.11)的模块,那个时候还没有完善的虚拟内存的机制。Buffer Cache以指针的形式存在,每个磁盘的Block(Block是文件系统概念现在一般是4KB,后文我们以1KB为例,Sector是磁盘概念一般是512B,文件系统以Block的方式管理磁盘上的Sector)在Kernel中对应一个buffer cache unit。文件读写时会首先计算出对应的buffer cache unit,然后直接读写buffer cache unit。然后buffer cache unit异步写回Block的Sector中。
- Linux-2.2版本时,Linux已经有了page的概念,buffer cache也以page的方式分配和管理内存。Page Cache是另外一个模块专门负责mmap部分的处理,而Buffer Cache实际上负责所有对磁盘的IO访问。如下图所示。可以看到非mmap的文件读写会绕过page cache,这就导致了不一致的可能。为了保证一致,非mmap读写会调用**
update_vm_cache**函数更新mmap的page cache保证一致。

- Linux-2.4版本之后,Page Cache、Buffer Cache的实现进行了如下图的融合。每个page对应四个block,所以每个page cache unit对应四个buffer cache unit实现了绑定(最新的文件系统一般block和page都是4KB了,两者的融合会更加直接)。文件系统以page为单位承接读写请求,磁盘以block为单位进行写入。通过这种设置page cache和buffer cache实现了融合,并都得到了保留。当进行写入时,内核只保留一份数据。与page cache是纯文件系统概念不同,buffer cache在无文件系统的环境中同样起着重要作用。当使用Linux提供的磁盘命令dd等时,不会通过文件系统,直接读写裸磁盘时,同样会使用buffer cache进行缓存。
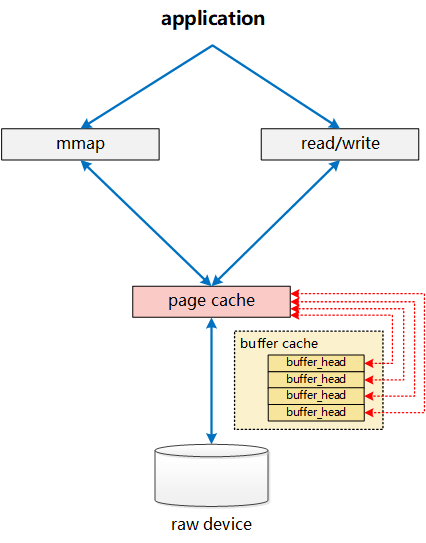
参考资料:
https://lday.me/2019/09/09/0023_linux_page_cache_and_buffer_cache/#第二阶段:Page-Cache、Buffer-Cache两者并存
https://zhuanlan.zhihu.com/p/308054212
多级cache
Cache一一般有几级,他们之间的关系是什么
- 主流x86平台一般有三级,分别是L1,L2,L3。L3因为是最靠近主存的也被成为LLC(last-level cache)。
- 多级Cache之间大概有四种关系(不正交)
- inclusive,上层存储的数据,完全包含于其下一级存储。
- non-inclusive,上层的数据可以 不在下一级存储里。目前主流的CPU,为了性能倾向于这一种实现。
- exclusive,数据是在某一层存储里是独占的。
- non-exclusive,数据在某一层存储里不是被独占的,其他的也有。
- 多级Cache之间通过统一大小(应该一般都是统一的)的Cache Line进行数据换入换出。通常Cache Line的大小是64Bytes。
可以参考https://zhuanlan.zhihu.com/p/109206967获得更详细的资料。
ICache和DCache在哪里?
ICache和DCache存在于L1Cache中,因为两者的使用场景不同(比如ICache一般只读)在L1Cache中做了区分,而在L2和L3中则是统一管理。有时候会出现ICache和DCache的一致性问题(比如GDB加断点需要修改指令),则有相应的软硬件技术来处理这种问题。具体请参考资料https://zhuanlan.zhihu.com/p/112704770
Cache一致性
什么是MESI协议
Zore Copy
Linux 如何实现零拷贝?
具体实现参考https://zhuanlan.zhihu.com/p/308054212
提供一个简单版本:大体上Zero-Copy是为了避免CPU多余的内存拷贝,通常用于通过网络传输文件时节省 CPU 周期和内存带宽。是一类技术或者一个概念,而非一项具体的技术。
实现技术大概有三种:
- 减少甚至避免用户空间和内核空间之间的数据拷贝,通过直接操作内核的内存(用户态操作映射后的地址)实现,mmap(),sendfile() 以及 splice()。
- 绕过内核的直接 I/O,DMA或者RDMA。
- 内核缓冲区和用户缓冲区之间的传输优化,动态重映射与写时拷贝 (Copy-on-Write)和缓冲区共享 (Buffer Sharing)等。
mmap
mmap的用途
-
跳过page cache直接进行读写,效率更高
-
内核和用户态的修改都会直接的反映在映射区域,是一种高效的用户态内核态交互方式
-
提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。
同时,如果进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
-
可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
参考资料
https://www.cnblogs.com/huxiao-tee/p/4660352.html
Copy-on-Write
TBA
C++相关
类型转化Cast相关
四种cast的区别是?
四种cast的用法都是
1 | ChildClass *cp = XXX_cast<ChildClass *>(ParentClass* pp); |
static_cast 内置类型可以随便转化。类的指针(也支持引用)可以在父子之间转化。在编译期处理,不进行验证。但是使用转化之后的指针有可能会出问题,最好在确定可以转化的时候使用。和C语言的类型转化接近。
dynamic_cast 与static_cast不同的是,发生在run time(RTTI, Run-Time Type Identification),且只能处理类的指针(或者引用)。如果检查失败,比如本身是父类的实例,转化为子类,会发挥nullptr。不过因为是run time,会有性能损失。
const_cast 用来除掉const或者添加const,比如const string -> string。不会失败。
reinterpret_cast 使用经过转换的新指针进行访问会按照新的类型一个bit一个一个bit的理解。比如对于一个int类型的num
1 | int num = 0x00636261; |
因为我们的系统一般是小端,所以在内存实际上存储的顺序是0x61,0x62,0x63,0x00,由于使用重新组织内存的方式,当按照Char*的方式来组织,这段4Byte的内存会被理解为字母'a', 'b', 'c', '\0'。如果我们printf(pstr)出来,便会输出"abc"。
dynamic_cast的大概原理
在大部分的编译器实现中(也就是说非C++标准),C++的多态使用虚表实现,每个有虚函数的类的虚表中,会有一个中会有个type_info字段。
查看https://en.cppreference.com/w/cpp/header/typeinfo
可以看到type_info中的接口:
1 | namespace std { |
可以使用type_id()来读取类的type_info的内容,对比type_info来判断类型是否一致。
dynamic_cast的具体实现需要参考具体的编译器。
后端相关
数据同步相关
Redis与MySQL双写一致性如何保证
前言:这个题虽然也是个八股,但是多少有点系统设计的意思了。
首先这里指的是数据一致性(也见过叫读写一致性的),不是数据库的事务一致性。数据一致性整体有两种(具体参考后文):
- 强一致性
- 弱一致性
- 需要专门提一下最终一致性
三个经典的缓存模式:
- Cache-Aside Pattern
- 读
- 读的时候,先读缓存,缓存命中的话,直接返回数据
- 缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
- 写
- 更新的时候,先更新数据库,然后再删除缓存。
- 读
- Read-Through/Write through
- 读
- 从缓存读取数据,读到直接返回
- 如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
- 写
- 先看在缓存是否存在,存在则先更新缓存然后再更新数据库最后返回;不存在则有两对应策略:一种是先将数据写入缓存,然后由缓存组件将数据同步更新到数据库;另一种策略是不写缓存直接将数据写入数据库。
- 读
- Write behind(Write-Back)
- 读同Read-Through/Write through
- 写与Read-Through/Write through也类似,在对数据进行数据持久化存储回写时一般采用异步回写,也可以间隔一定时间后批量回写。
- 适用于这一策略适用于多写的情况。但是先写数据库再更新缓存,可能带来数据的不一致,读取的延时。
强一致
上述的简单三种策略几乎都无法保证较强的一致性,甚至无法保证最终一致性。如果需要强一致,那最好的办法还是两阶段协议保证更新,但是如果这样还不如让使用其他一致性策略,让强一致需求的请求直接操作MySQL,弱一致的读Redis。
弱一致
保证最终一致性的终极解决办法是使用TTL,让Redis上的数据过期后重新从MySQL上拉取。
其他更弱的一致性可以使用一些更宽松的策略,比如之前提到的三种缓存模式。
上面是从策略的角度纵向分析,从读写策略的角度横向分析的话,读比较简单,命中直接读,未命中要么读数据库返回并Dirty Cache,要么读完先更新Cache再返回。两种策略区别不大。
写的策略相对复杂一些,大概有四种:
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
- 先更新缓存,再更新数据库
- 先更新数据库,再更新缓存
3和4在多线程情况下,由于两层存储写入步调不一致,都非常容易出现数据不一致的情况,比如出现脏数据等。主要是Read-Through/Write through和Write behind(Write-Back)两种场景使用。一般在以读为主或者需要较高一致性的场景用的不多。
对于1(先删除缓存,再更新数据库):
1问题很明显,读操作是先读数据库(假如发现Redis Miss),再更新缓存。写操作确实先改变缓存,再更新数据库。读数据库还比写数据库慢。很有可能出现下面的不一致场景:
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库
如果没有TTL或者新的写操作,B写入缓存的数据会一直成为脏数据。如果MySQL上是读写分离架构(主上写,从上读,非强一致),主上的写和从上的读同样会有类似的问题。
一个简单的解决办法是,写请求,在经过一段时间之后进行二次删除(延时双删策略)。代码来说:
1 | public void write(String key,Object data){ |
sleep的时间需要根据业务来决定。虽然不能根治上述问题,但是可以很大程度缓解。Sleep代来的延时可以用异步的方法回避。最终带来的Overhead仅仅是多一次Redis Miss。
不过如果第二次删除因为各种原因失败了,还是会出现不一致。相对来说,方案2中出现这种情况的概率会小很多,是更常见的解决方案。
对于2(先更新数据库,再删除缓存):
也就是之前提到的Cache-Aside pattern策略。Facebook的Scaling Memcache at Facebook中提到,Facebook使用了同样的方法。由于此时读写(Redis Miss的时候)都是先操作MySQL再操作更新Redis。不会出现之前的情况。但是可能有另一种不一致(这一种不一致同样会发生在策略1):
- 缓存刚好失效
- 请求A查询数据库,得到一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查到的旧值写入缓存
这种情况同样会发生数据不一致。但是只有在读MySQL延迟特别高,高到允许写操作写完MySQL再写完Redis的时候才会发生。但是一般读操作延迟比写都低,所以实际发生可能性不大。使用之前提到的延时双删策略,可以进一步减少这种可能。
关于延时双删策略,第二次删除失败,解决方案主要还是重试。可以选择直接让业务代码进行重试。也可以用异步的方式进行重试。或者订阅MySQL的BinLog来异步删除。
总结:综合下来如果不要求强一致(这种场景可能也很少需要强一致),在多读少写的场景下,使用Cache-Aside Pattern,结合延时双删和重试,是更好也是更常见的选择。
参考资料:
https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
https://segmentfault.com/a/1190000040709794
https://www.daimajiaoliu.com/daima/8c79f95dc1ab809
分布式相关
一致性相关
区别数据一致性和事务一致性?
数据一致性,CAP里面的C。针对数据复制导致的多副本可能不同步,核心的判断标准是全局各个副本读写顺序的一致性(可以粗放地理解为读到和写到的内容的一致性)。
强一致性:读写顺序全局一致,比较经典的理解方式是在主副本的写完成后,从副本上立马可见最新的更新。具体来说强一致性包含两种
- 线性一致性(Linearizable Consistency),在强一致的条件下,加入了读写顺序必须和全局时钟一致(具体的表现,实际的读写顺序和client上读写请求发出的顺序匹配),目前因为做不到全局时钟,所以无法实现。
- 顺序一致性(Sequential Consistency),不需要和全局时钟一致,全局统一就可以了(client上先发出地读请求可能在后发出地写请求之后,在server上执行)。一般强一致就是这种。
弱一致性:不是强一致的其他一致性,读写顺序全局不一定一致。常见的主要是:
- 因果一致性(Causal Consistency),传说中的 ”Happened-Before“,可以参考Lamport的 Time, Clocks, and the Ordering of Events in a Distributed System, 简单来说,因果一致性只保证有因果顺序的请求读写顺序一致。对于没有因果关系的,不保证。因果顺序是一种偏序关系,公式表达为:如果o1和o2满足因果顺序,记为o1→o2:
- o1和o2属于同一个进程,且o1在o2前面执行。
- o1是个写操作,o2是个读操作,且o2读到的值是由o1写入的。
- 存在一个操作o’,满足o1→o’→o2。
- 最终一致性(Eventual Consistency),只保证所有副本的数据最终在某个时刻会保持一致。比因果一致性更弱,基本上就是所有的数据库都能保证。一些不严肃的场景不在意丢数据可能会连最终一致性都不保证。
- 除了上面两种还有一些以客户端为中心的一致性(Client-centric Consistency),用的不多,暂时不详细解释了,感兴趣可以参考后面的参考资料。
- 单调读一致性(Monotonic-read Consistency)
- 单调写一致性(Monotonic-write Consistency)
- 读写一致性(Read-your-writes Consistency)
- 写读一致性(Writes-follow-reads Consistency)
事务一致性,ACID里面的C,似乎很多人把这个C和CAP里面的C搞混。其实主要指的是数据库里面的各种约束(constraints, cascades, triggers, and any combination thereof),不会被任何情况打破(比如重启,crash,新的读写等)。永远Valid。
参考资料:
https://zhuanlan.zhihu.com/p/59119088
https://lamport.azurewebsites.net/pubs/time-clocks.pdf
https://en.wikipedia.org/wiki/ACID#Consistency_(Correctness)
