前言:
这篇博文是我受一次面试启发后,搜集信息完成行业调研完成的。主要内容是流数据库(Streaming Database)的一些概念,技术,系统和对应公司的情况。大部分内容是从互联网上各处搜寻来的,也有一部分是我和一些从业人员或者基础架构领域的前辈交流得来的。除此以外,我也添加了一些我个人关于这些系统以及整个流数据库行业主观判断和想法。
文章定位是帮助技术朋友们快速了解这个新方向,并给金融行业朋友提供一些技术的视角。
完成的时间大概是5月份,最近临开学,时间比较充裕,才有机会搭建博客并把这篇文章发到互联网上。也因此里面的一些内容可能有一些时效性不足(其中企业的融资情况我特地更新了一下,应该是最新公开信息了),欢迎诸位读者朋友评论或者邮件与我交流。如有内容错误的地方也欢迎批评指正。
Overview
本文主要对流数据库这一新兴数据模型和商业模式进行了调研和分析。首先介绍了介绍流数据库相关的基本概念,然后阐述了流数据库的基本定义及价值意义。接着对流数据库系统的典型技术路线和典型系统及其对应企业进行了分析。最后分析了流数据库与相似数据模型的区别。
流数据
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达。
- 实例:PM2.5检测、电子商务网站用户点击流
流数据具有如下特征:[1]
- 数据快速持续到达,潜在大小也许是无穷无尽的。
- 数据来源众多,格式复杂。
- 数据量大,但是不十分关注存储,一旦经过处理,可能被丢弃或归档存储。
- 注重数据的整体价值,不过分关注个别数据。
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
流数据库定义
定义
不同于其它数据库系统将静态的数据集(表或文档等)作为基本的存储和处理单元,流数据库是以动态的连续数据流作为基本对象,以实时性作为主要特征的数据库。流数据库是数据库在流时代的重新架构和设计。[2]
A streaming database is broadly defined as a data store designed to collect, process, and/or enrich an incoming series of data points (i.e., a data stream) in real time, typically immediately after the data is created. This term does not refer to a discrete class of database management systems, but rather, applies to several types of databases that handle streaming data in real time, including in-memory data grids, in-memory databases, NewSQL databases, NoSQL databases, and time-series databases. [3]
上面是两家公司从流式计算的一些场景给出的streaming database的定义。
从技术角度讲,本文作者认为,流数据库的典型特征基本是,在SQL数据库的基础上,使用物化视图为代表技术进行数据库请求的性能调优以实现低延时,并通过技术手段优化减少性能调优带来的资源占用。
流数据库的作用和生态地位,可以用下面的简化抽象,不太准确但形象地表示出来的:
假如我们有很多不同颜色的小球通过管道源源不断传递过来,我们希望统计每个颜色小球的数量,那么传统的大数据架构会如下图工作(忽略流式处理,位置和AP差不多):

由于统计和接受小球(数据)需要使用不同的底层架构,传统大数据会分开处理两个任务,用一个叫OLTP的桶来接球,然后定期用泵(各种中间件MQ等)把一批小球泵到一个更大的叫做OLAP的桶,然后这个OLAP的桶再慢慢去按照颜色统计小球的个数。
而流数据库的统计小球会像下图来工作(后文C类型工作模式为例):

流数据库会在接收数据的同时,尽可能实时的现时桶里面按颜色统计的结果。如果我们打开streaming database这个桶看,我们大概会看到这样的景象,桶内有提前布置好的管道,新的进入后直接流入对应的分区,从而实现实时统计数目。

关于Streaming Database和OLAP的更多对比或者tradeoff,可以参考后文”流数据库&时序数据库&OLAP“章节。
区分于Streaming SQL
为了支持对流式数据的支持,在Hadoop平台上Apache标准内有一些针对的Streaming数据的类SQL标准。比如由Apache Calcite的stream接口提供的Streaming SQL[4] ,Confluent的KsqlDB中定义的KSQL。
Calcite是一个面向Hadoop平台的SQL引擎,起源于Hive后,独立成为Apache项目。秉持着one size fit all的思想,其优良的模块化设计,使其成为众多计算引擎的SQL解释/优化层,可以将SQL或StreamSQL[4:1] 转化为不同层级的运算任务[5],Beam,Flink等系统均基于Calcite架构进行实现[6]。
区分于Streaming Analytic
Streaming Analytic流处理引擎是流数据另一个非常热门的话题。许多公司和机构都有自己的流式引擎,比如最早在2003年Stanford提出CQL Continuous Query Language时作出的原型系统STREAM,就具有一定的处理流数据的功能。2008年IBM开始对外销售并不断更新自己的流式引擎The System S[7]。Storm是最早作为流失计算引擎大规模使用起来的系统,此后此后各个互联网公司纷纷基于开源实现或者从零开始搭建了属于自己的流式引擎或者流式计算平台,比如谷歌的Millwheel,Dataflow,Azure的Stream Analytics,Amazon的Kinesis和Twitter的Heron。开源社区也有非常多经典的实现,比如Apache旗下的Storm、Spark Streaming、Flink、Samza、Apex等都是经过了时间的考验的系统。此外还有专门提供通用引擎框架的部署框架Beam和具有可移植性的SQL框架Calcite。
流处理引擎和流数据库是两个不同定位的系统,流处理引擎试图解决在类似Hadoop大数据场景下,对持续海量数据的持续处理需求。其自身不包含对数据本身的存储功能,只是读取数据计算结果并进行计算。而流数据库既关注对流数据的持续处理能力,也承担对流数据的存储和管理能力。
对比
Streaming Analytic流处理引擎和流数据库的使用场景对比可以参考下面的表格(其中的Streaming Database中的内容主要参考后文中提到的几个比较现代的流数据库的信息)
| 对比项目 | BigData Streaming Analytic | Streaming Database |
|---|---|---|
| 延时 | 1s - 1min | 10ms - 1s |
| 容量 | PB | TB |
| 资源消耗 | 正比于数据量 | 正比于数据量到数据量的平方 |
| 运维成本 | 高 | 低 |
| 使用场景 | AP场景,ML场景 | AP场景 |
| 自由度 | 高,可自由编写task | 中等,sql标准内的操作 |
| 数据持久化 | 不持久化 | 可以支持持久化 |
区别于Streaming Platform
对比
Streaming Platform是对Streaming Analytic流处理引擎能力的完善,通常的做法是在流处理引擎周边补充完整的数据存储系统和消息中间件,使流处理引擎成为一个完整的平台。可以完成收集,处理,存储整个流处理流程。
Streaming Platform和Streaming Database具有大部分相同的功能,在定位上有不少重合,但是也有一些不同点。
- 现有Streaming Platform通常提供Streaming SQL的语义,核心任务仍然是流式计算本身,不关心数据的存储功能。而Streaming Database旨在提供标准SQL或者PgSQL的语义兼容,不仅提供流式处理请求的能力,也需要拥有一定的正常TP或LP功能。
- Streaming Platform本质上是多个系统耦合而成的大工程,包括消息队列,计算引擎,编排调度,存储系统,以及相关周边系统。相反,Streaming Database提供一站式服务体验。这一点类似于SQL-on-hadoop与普通分布式RDBMS的关系。
- 性能上说Streaming Platform服务的规模更大,延时更高达到秒级甚至分钟级,Streaming Database服务的规模较小,延时可以达到亚秒级。
现有流数据平台
相对来说互联网巨头更倾向于使用这一种模式来完成Streaming的一系列工作。而Streaming Database往往定位到没有足够能力驾驭如此巨大系统的中小型公司。业界有一定知名度的Streaming Platform包括:
- AthenaX是Uber开源的Streaming Platform,基于Calcite和Flink进行SQL的运算,数据持久化到LevelDB上。
- Keystone是Netflix内部的Streaming Platform,使用Flink做计算引擎,spinnaker做编排调度,数据落盘到 AWS RDS上。
- Turbine[8][9]是Facebook内部的Streaming Platform,使用大量内部的系统实现,目标是提高现有流计算系统的可延展性
- SnappyData[10]是一个基于Hadoop的半开源系统,企业版(ComputeDB)由TIBCO收购并反哺开源社区。SnappyData支持了行存和列存(但是对于每份数据只能二选一)。使用Spark Streaming实现Streaming Procsessing功能,GemFire实现TP功能,Spark实现AP功能。在一个系统上实现了Streaming,TP,AP系统。其企业版ComputeDB已经很大程度上具有数据库功能,但是并没有使用Material View进行优化。
- 国内东方国信同样也曾推出过类似的系统CirroStream[11],但是资料有限。
- 以上主要是公开信息中可以找到的一些系统,此外国内大厂中应该也会有自己的一套体系,比如据了解字节内部类似的系统被称为DataLeaf。更多信息欢迎有了解的朋友邮件与我沟通。
流数据库诞生的背景
现有大数据流处理模式
现有的提供流处理能力的系统本质上是类似于SQL-on-Hadoop的解决方式,使用多个系统整合,形成一个平台式的大系统。互联网厂商通常会有自己的平台完成这一任务,也有一些经典的框架来完成这一工作,比如Lambda架构、kappa架构[12]、SnappyData等均可以在一定程度上将一个大数据系统封装成为一个类数据库的平台。但这带来了巨大的使用成本,包括运维复杂性,资源需求等。应运而生的需求便是一个具有流处理能力的一体化,可控,方便运维,对数据量要求不高的数据库。[10:1]
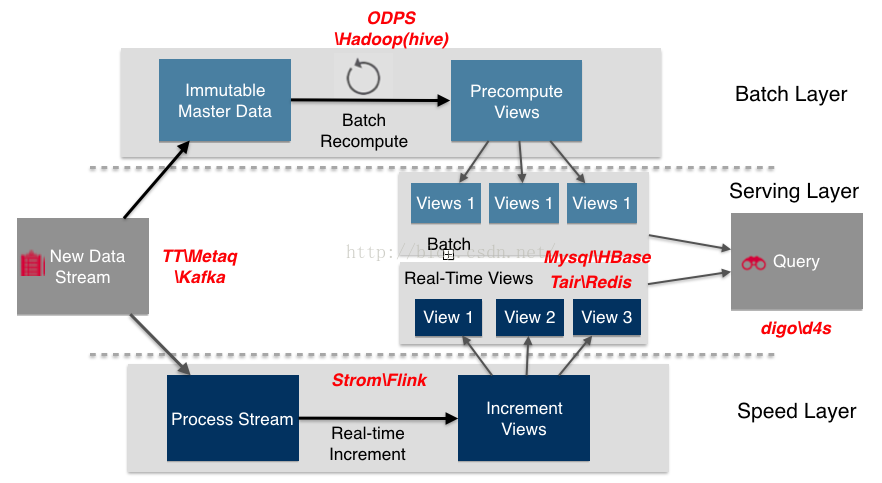
现有数据库体系的复杂性
现有数据库体系同样可以在一定程度上完成多读,大量读请求的场景。现有数据库+Cache+分布式组件的模式可以依靠层级存储,达到较低的延迟。但是与大数据流处理模式相同的是,这种模式同样需要多个系统协作,例如Facebook中对Cache层使用mcrouter进行协同,使用mcsqueal进行cache层和数据库层的协同。这同样带来了高复杂度和维护成本。此外,数据不一致,同步效率低也是这一体系的天然弱势。对此产生的需求是,一体化,低同步成本,高同步效率的系统。
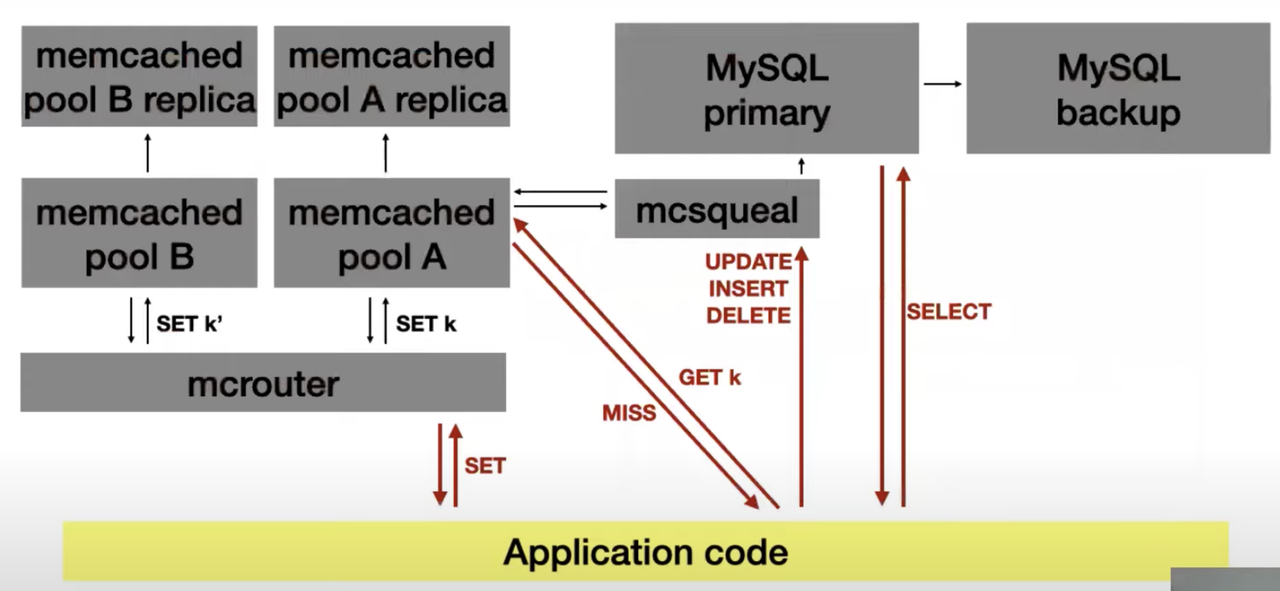
大量中小型公司的query相对固定
随时移动互联网大环境的发展减缓,各个公司的业务相对成熟和稳定,很多公司的业务下对数据的访问也逐渐稳定。访问固定,但是数据不断产生成为新常态。
query延时敏感的应用越来越多
根据国际知名分析机构 IDC 的研究报告[13],实时的流式数据占总体数据规模的比例正不断攀升,预计 2025 年能达到 30%。(字节在20年底,流式计算的计算规模已经赶上批式计算,预计将在21年实现超越。)营销,风险防控,商业决策对数据的实时性要求越来越高。对底层读能力的考验越来越严峻。[14]
流系统和流数据库
处理流系统中的延时问题,通常来说有几个解决途径,a.放松一致性的要求,b.进行预计算,c.添加集群规模,d.极致的工程优化。流数据库试图使用在a,b,d中进行平衡实现最好的性能体验。目前整个数据库领域,流数据库仍然是一个非常小众的方向,在著名的数据库排行网站DB-engines[15]上,也还没有将Streaming Database作为一个数据库方向。
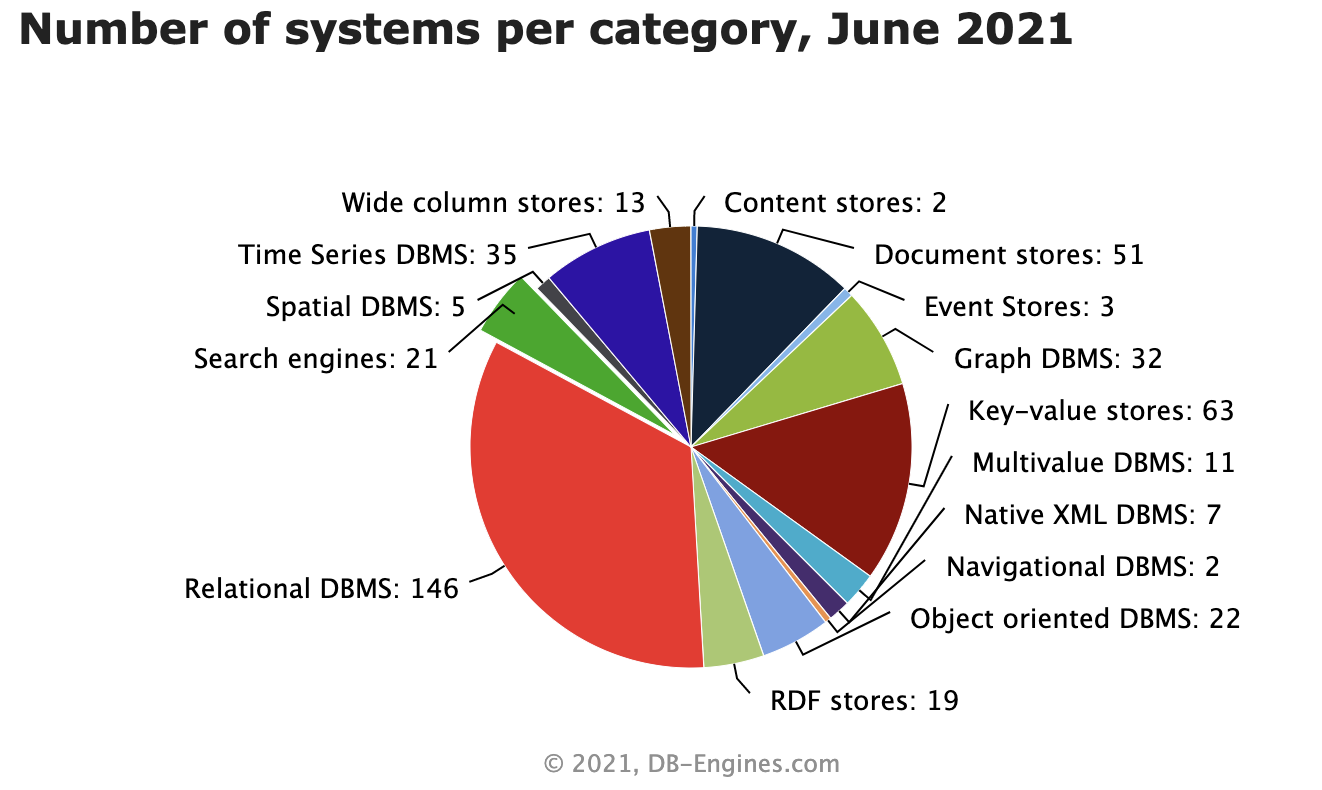
流数据库的应用场景
- 在泛机器学习领域上,流式数据可以提供快速的模型更新,辅助模型做出更加即时的决策。
- 在工业互联网/物联网(IOT)领域上,设备上的传感器将“流数据”持续不断的发送到流处理平台,实现对机器设备的监测,对生产风险的预警,防止重大生产事故的发生。
- 在金融风控领域上,通过实时跟踪贷款人的金融行为“流数据”,检查异常客户,及时报警和逾期客户的失联修复。
- 在商业营销领域上,可以通过检测客户的实时位置“流数据”,推送基于地理位置的广告信息,比如餐厅、商场、加油站等。
- 在新媒体领域上,通过对数十亿的在线内容点击“流数据”进行流处理,优化网站上的内容投放,为用户提供最佳的用户体验。

技术路线
Streaming Database的典型特征是Materialized View[16],通过Materialized View进行预计算以达到请求低延时的需求。
部分传统数据库同样可以Materialized View的支持提供类streaming功能,比如MongoDB上的 Change Streams[17],PgSQL和Oracle提供View Maintenance的功能。但是普遍对Materialized View的支持都不完善,也没有专门对此进行资源和性能优化等。
典型的分析模型

如图是一个典型的分析模型,数据写入TP,然后通过Debezium转化做流,发给AP分析之后application才可以读到数据。这也是大部分大数据场景的基本架构。
使用方式
流数据库这一方向还没有一个具体的标准,不同厂家的流数据库往往具有不同的使用方式或者生态地位。
调查各个现有的系统总结归纳之后,流数据库streaming database的模式基本有如下三种:
A类型的作模式

B类型工作模式

C类型工作模式

市面上的系统
| 对外发布时间 | 开源状态 | 开发进度 | 企业 | 工业级 | 与消息队列关系 | 开发语言 | 语义 | 存储引擎 | 增量分析 | 支持的工作模式 | Feature | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noria | 2018 | 完全开源 | 暂无更新 | BrownU | 否 | 从MQ读 | Rust | MySQL | rocskdb | 支持 | 支持C模式 | SQL支持 |
| Materialize | 2020 | BSL 1.1,单机开源可用 | 持续迭代 | Materialize | 是 | 从MQ读 | Rust | 大部分PgSQL、标准SQL | 未披露 | 支持 | 支持AC模式 | SQL支持 |
| HStreamDB | 2021 | 按揭开源 | 框架搭建中 | EMQ | 否 | 包含MQ功能 | Haskell | 自研StreamSQL | RocksDB Hadoop | None | 支持ABC三种模式 | Tiered Storage/Rust/SQL |
| ksqlDB | 2019 | 基本开源,只能用,不能Saas卖 | 持续迭代 | Confluent | 是 | 是kafka的扩展 | Java | LightWeight SQL、自定义Streaming SQL | Kafka rocksdb | 不支持 | 支持BC三种模式 | 专门针对流,放弃了部分SQL语义,非读写强一直,支持了云原生 |
| RethinkDB | 2009 | 开源,有商用版本 | 半死亡 | YC -> (2016)CNCF | 是 | 从MQ读 | C++ | 类MongoDB ReQL | B+tree + LSM | 不支持 | 支持C模式 | 类似于mongodb的推式数据库,SSD的充分利用 |
| PipelineDB | 2013 | 完全开源 | 死亡 | PipelineDB | 否 | 从MQ读 | C语言 | 完整的PgSQL和StreamSQL | PgSQL | 支持 | 支持C模式 | 是PgSQL的插件,为PgSQL添加了流的概念,SQL支持 |
| Rockset | 2018 | 闭源 | 持续迭代 | Rockset | 是 | 从MQ读 | C++ | 完整的SQL | Rocksdb | 不支持 | 支持AB三种模式 | 高性能,快速查询,使用聚类索引的方式,提供完整sql |
已关闭的产品
RethinkDB
RethinkDB[18]最早是作为一个对SSD进行专门优化的MySQL存储引擎出现的,其特点在于对SSD的充分利用。而目前RethinkDB已经脱离MySQL成为一个独立的存储。RethinkDB是自底向上为实时网页设计的第一个开源的、分布式的、可扩展的数据库,提供类似于MongoDB的功能,具有强大的集群和自动故障转移功能。传统数据库使用的是一种查询——响应数据库访问模式。
RethinkDB使用了新的数据库的访问模型,而不是轮询数据库更改,开发者可以命令RethinkDB实时的向应用连续推送更新查询结果。这使得搭建现代、实时的应用程序十分方便:开发者可以得到一个可扩展的实时Web应用程序的App,并在用一小部分时间运行的同时使用更少的工程资源。
RethinkDB的核心贡献是给出了新的数据库访问模型,使数据库请求的实时性得到跨越。
PipelineDB
PipelineDB[19]由PipelineDB团队于2013年创立,2016年正式开源,2018年被confluent收购,从此停止维护。
PipelineDB本身不是一个完整的数据库,而是一个类似于数据库插件的系统[20],他改造了PgSQL系统,为其增加了功能,实现了流处理的功能[21]。具体来说其为PgSQL添加的三个核心概念是
- Stream是类似于表的概念,用来承接数据。
- Continuous View可以看作是可以实时更新的Materialize View。提供了Incremental Update的能力。
- Continuous Transforms是一个中间状态,类似于一个不存数据只当管道的Stream。这一机制已经类似于Noria等系统中的operators
PipelineDB通过这三者加上对SQL的扩展,实现了流处理的功能。PipelineDB的优秀之处在于,PipelineDB除PgSQL之外没有添加更多的依赖,以PgSQL的插件方式存在就实现了流处理的需求,是一个极其简单的设计,并且其对stream的定义,大大丰富了流处理的能力,是流处理系统早期的经典之作。其缺点在于,实现方式比较原始,有占用额外资源多等问题。
被收购后,由于没有继续维护,年久失修,BUG众多,已经很少再被用到生产环境中。
现存的产品
DBToaster
DBToaster不是一个纯粹的数据库。是洛桑联邦理工学院数据实验室开发并于2009年对外公开的的数据流查询系统,提供从 SQL 查询语句到生成本地代码的编译框架。DBToaster可以使用storm进行计算,底层可以接入不同的存储系统。并使用Materialized View进行查询的优化。虽然不是流数据库,但是是早期比较专注于处理流数据的系统,具有一些流数据库的雏形,在一些人眼中也被视为流数据库。查询其官网发现,DBToaster已经多年未继续维护了。
Noria
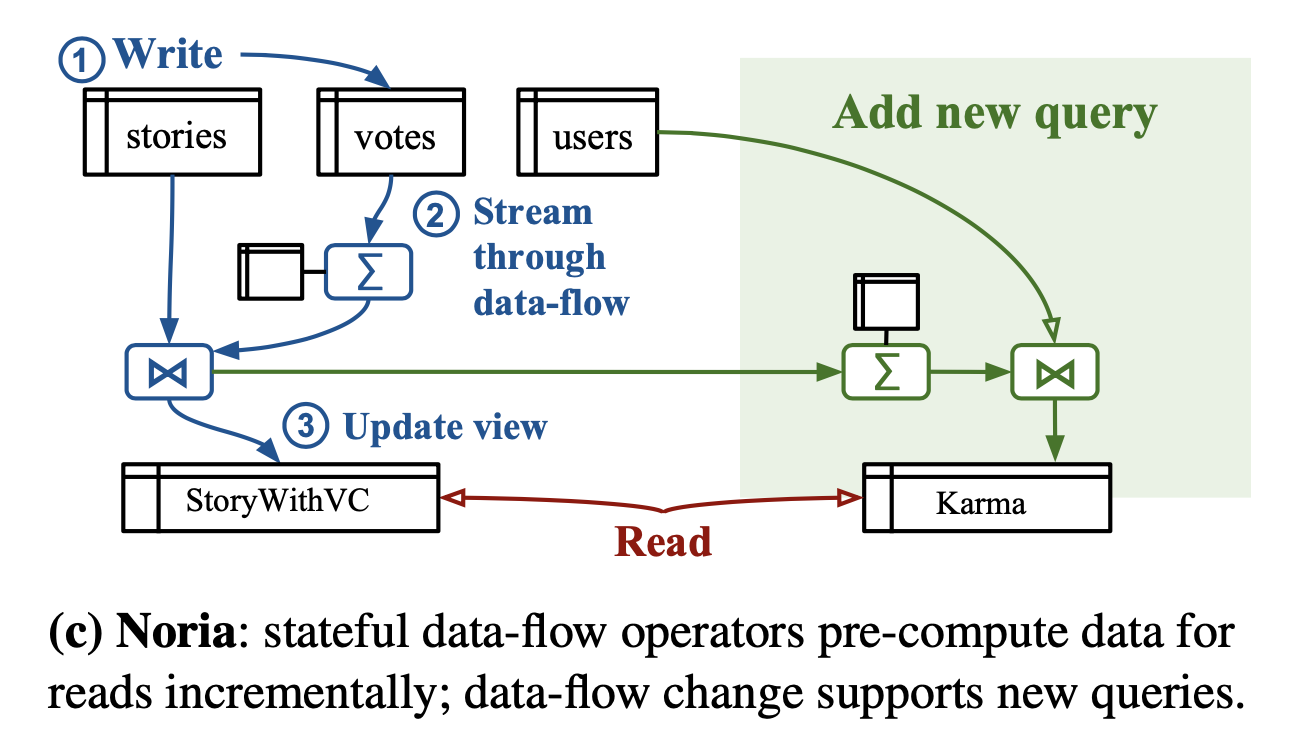
Noria[22]是MIT CSAIL实验室的Jon Gjengset, Malte Schwarzkopf等人发表于OSDI 18的一个数据库系统[23],曾被Adrian Colyer评选为18年OSDI的The Morning Paper之一[24]。他们将自己的系统定位于服务高性能(低延迟)需求的高读取量web应用程序。虽然paper中没有明确指出Streaming Database一词,但是已经具有了Streaming Database的流处理能力,高性能访问,数据持久化等特征[25]。

其核心Idea叫做partially-stateful data-flow。基于现有的Materialized View机制主要完成了几点优化
- partially-stateful是这篇文章的独到之处,Materialized View不再进行全量的填充,而是默认不填充,当数据真正被访问才会向上访问 upquery再进行填充。这会带来数据第一次访问的高延时,但是后续访问可以大大加速。Materialized View提高了性能,Partial的模式极大节省了Materialized View所需要的内存。
- Query复用,Noria会将数据进行DAG分析,形成一个operators流图。如果query之间有相同的查询内容,可以直接服用。
- 基于上述复用机制,支持了Live模式的Query添加,Query添加时,只需要在适当的位置添加新的operators就可以了。
Noria试图在现有数据库上做优化和调整支持新的流数据的需求,取得了比较好的性能。同时这篇paper也有一定的局限性,由于Materialized View的额外空间,Noria实际上使用了更多的内存,数据显示Noria在Lobsters上占用了大约三倍的内存。由于Noria只支持MySQL协议,未对Streaming进行扩展,实际上对流数据的功能有一定的局限。由于设计上没有针对一致性做过多的约束,读写一致性仍然只能达到最终一致性,这一问题在FlightTracker这篇paper[26]中得到一定的解决。
Materialize
Materialize[27]是由Materialize公司开发,BSL 1.1协议下半开源(仅可以使用单机版本)的一个流数据库,他们将自己定义成OLVM (Online View Maintenance)[28],对外他们提供PostgreSQL语义(实现大部分功能)的接口,可以从Kafka等消息队列或文件中读取消息作为输入。
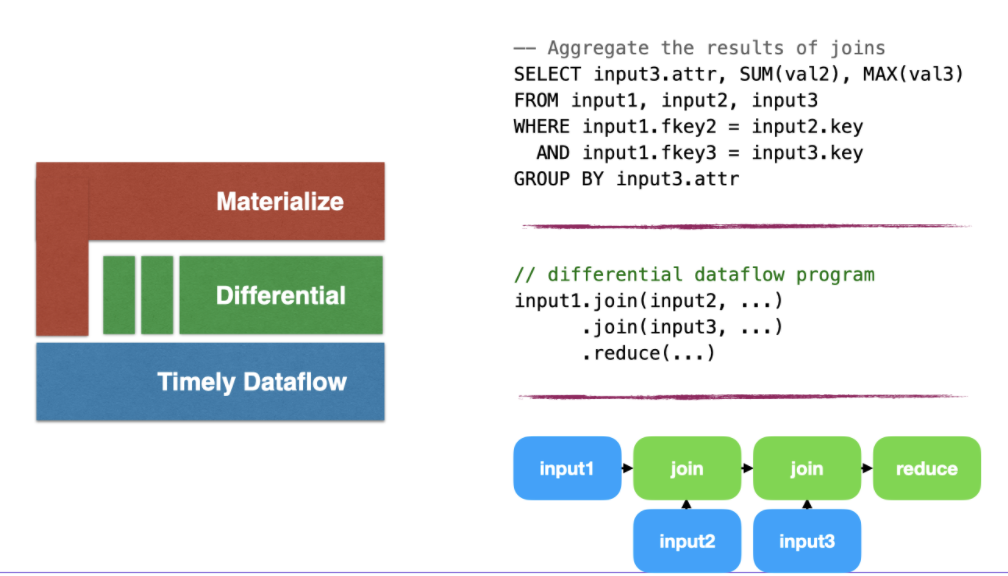
Materialize基于Timely Dataflow和Differential Dataflow这两个同样由Frank McSherry完成的系统构建而成。这两个系统的原型Naiad是SOSP 13的best paper之一。实现分布式系统上的增量计算,流处理,以及一致性的保证。
Timely Dataflow的是一个分布式的计算引擎,上面可以定义有向循环图。Timely Dataflow使用时间戳的方式实现了增量计算和一致性保证。
Differential Dataflow基于Timely Dataflow对请求进行处理,将请求和数据拆分多个差别来进行计算。
基于上述两个系统,Materialize也可以作为一个单独的流数据处理引擎来使用。
但是与Noria类似的是,Materialize提供的是SQL接口,没有提供直接的Stream概念(比如windows)在他们的SQL中,同样不能直接对数据进行类似于时序数据库的基于时间的分析。
ksqlDB
KsqlDB[29]是由Conflunt公司开发维护的一个流数据库,是他们的产品KSQL的继任者。
KSQL是一个基于Kafka的流处理层,可以直接对Kafka中的数据进行分析,分析结果仍然是流。提供Kafka语言的push和pull,但是不支持正常的读写功能即SQL支持。在Kafka系统上做了Stream和Table两层抽象,来分别表示离散连续数据表(比如访问记录表主要的操作是append),和关联型数据表(比如个人信息表主要的操作是update)。最终其提供的功能类似于一个Kafka的外挂模块,可以将Kafka指定的一个或多个Topics下的数据,转化成新的流。
KsqlDB弥补了一部分上述功能的不完善,用Rocksdb添加了持久化层,并添加了各种KafkaConnect以从不同的数据源获取数据。同时添加了轻量的SQL支持,并且添加了对Materialize View的支持,实现了流处理引擎到类关系型数据库的转变。不过由于对于Materialized View的操作是异步操作,牺牲了读写一致性,提高了吞吐降低了延时,但是无法和OLAP数据库的可靠性进行对比。
在实际使用中,其地位仍然不是真正的数据存储,而是针对不停修改的数据库内容的Materialize View外部存储。在KsqlDB中定义Materialize View后,KsqlDB通过connector监听各个数据库或者app的数据变化或者新的数据,形成数据流,使用ksql进行计算并落到rocksdb持久化的Materialize View上。当有请求进行访问时可以直接以SQL的模式返回结果。

Rockset
Rockset[30]给是Rockset公司研发的数据库系统,并不是一个流数据库,其自身的定位是“实时分析数据库”,但是具有一定的对流式数据的处理能力。Rockset试图解决两个数据库长久以来的矛盾,一个是综合处理结构化和非结构化的数据,一个是同时做到高速更新和低速查询。给出的解决方案是Relational Document Model和海量索引。在关系型的基础上,使用动态模式自动展开嵌套处理文档等非结构化数据。使用大量索引提高查询的效率
Rockset严格来说更像是一个OLAP产品,但是其运行的数据级并没有达到PB的级别,相对更集中在GBTB的规模上,其公司自称为OPAP(OPerational Analytics Processing),被理解为运营级数据分析。其高性能快速查询的能力,对流式数据的处理能力,都和streaming database提供的能力有一定程度的吻合。但与streaming database不同的地方在于,Rockset不依赖预先设定好的query进行预运算,更灵活,但是其在复杂query上的性能可能并不如streaming database。
在技术特点上,其使用的是为所有数据建立聚合索引的方式进行提速。这种模式有一定的空间和性能损失,但是相比Materialize View具有更高的Query灵活性。此外Rockset使用Rocksdb进行索引的持久化,并使用rocksbd-cloud功能实现了存储计算分离云原生化[31]。
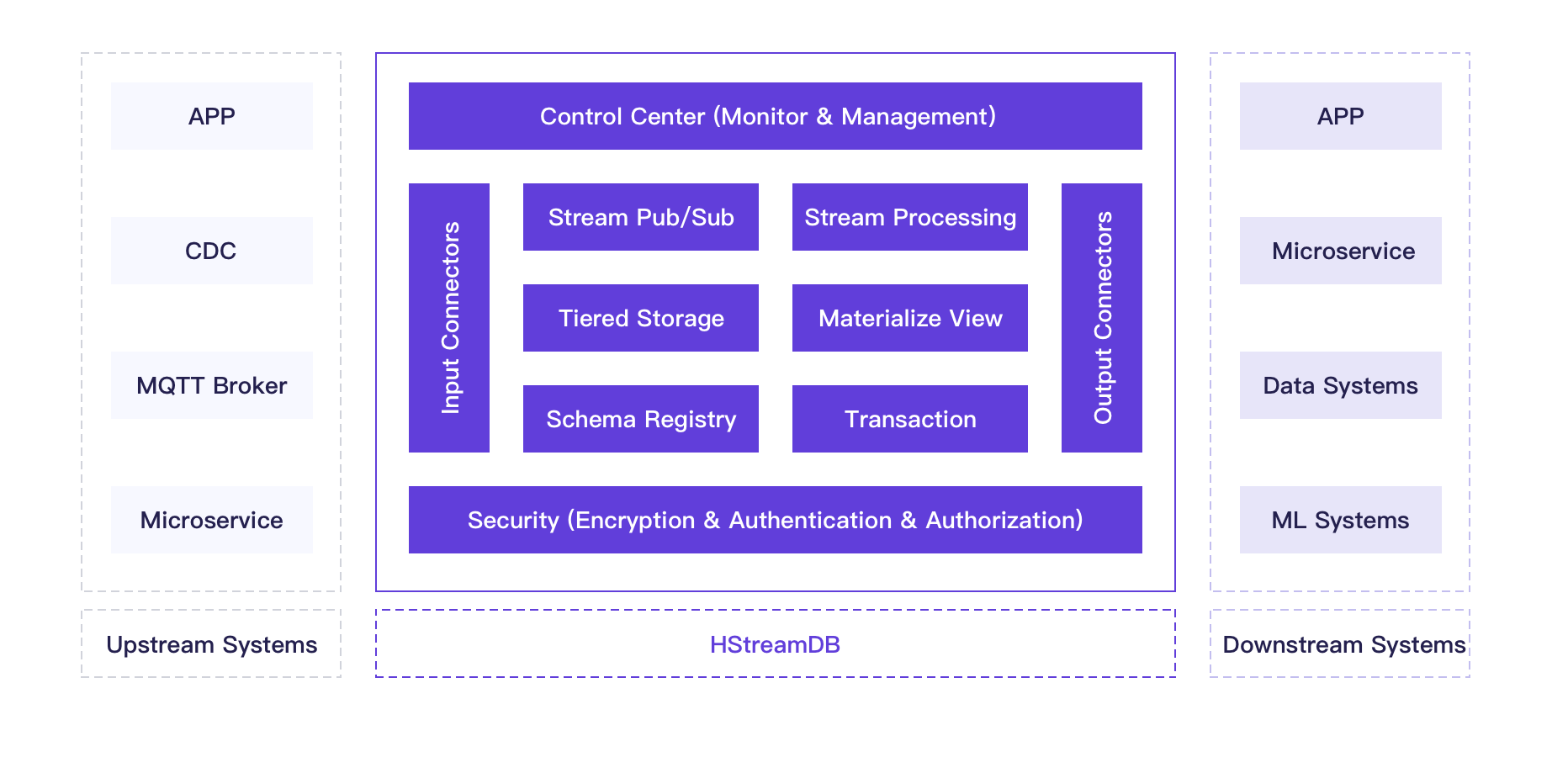
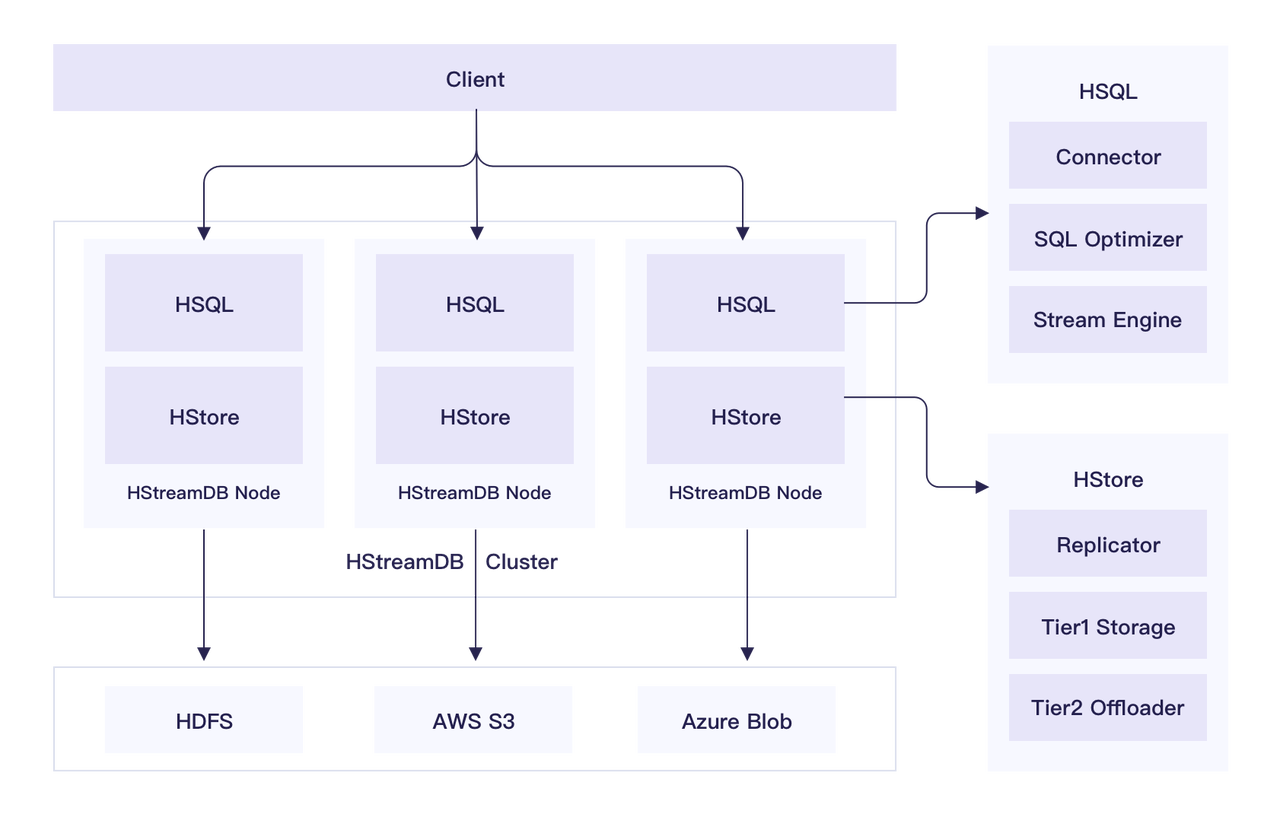
HStreamDB
HStreamDB[32]是EMQ自2021起开发维护的流数据库,已经开源。但是目前规划的功能还没有实现,尚在逐步迭代发展中。根据其架构,该产品预计有以下特点
- 具有一部分MQ的功能,可以处理海量请求,并快速的将这些请求记录下来,然后进行分析。天然高吞吐。
- 支持Tiered Storage可以将Dump到云平台以实现数据持久化。
- 同样基于Materialize以达到低延时的效果。
- 丰富的运维能力和安全体系。
- 较为完善的SQL能力和流处理能力。
Rapids StreamDB
Rapids StreamDB[33]是一家国内公司博睿数据开发的流数据库。其公开资料有限,根据其官网上的设计图等信息,可以推测其设计方向为:
- Materialized View加速访问,支持增量更新
- 纯内存数据库,不进行落盘
- 以Kafka等大数据系统产生的流数据作为数据源
- 经典的MPP架构
- 支持标准SQL
QFLOW
QFLOW[34]是国内初创企业快立方qcubic的流数据库,暂无太多有效产品信息。根据其官网,其目标是兼容标准SQL的内存流数据库。但是自首篇PR之后就找不到其他信息了,不知道有没有继续推进。
市场
市场规模
本文作者也不是金融出身,也没钱买专业数据,就不强行评估了,不过可以看看相关的一些数据。
根据MarketsAndMarkets的评估[35],2020年全球Cloud database and Database as a Service (DBaaS) 的市场规模大概是120亿美元,并以平均15.7%的年增速增长,预计2025年达到248亿美元。
根据MarketsAndMarkets的评估[36],2021年全球Data Warehouse as a Service的市场规模大概是47亿美元,并以平均22.3%的年增速增长,预计2026年达到129亿美元。
根据MarketsAndMarkets的评估[37],2020年全球整个Streaming Analytic的市场规模大概是125亿美元,并以平均25.2%的年增速增长,预计2025年达到368亿美元。
根据MarketsAndMarkets的评估[38],2020年全球Cloud Analytics的市场规模大概是232亿美元,并以平均23.0%的年增速增长,预计2025年达到654亿美元。
拍脑袋算的话,作者估计可能2020年大概是40亿美元,2025年大概100亿美元。
streaming database这个行业整体还算蓝海,说不好以后的发展。这或许取决于streaming database未来会变成streaming和database的交集,还是并集。
企业
国内
映云科技EMQ - HStreamDB
EMQ诞生于2017年4月。
18年4月获晨晖创投领投的种子轮投资,具体金额未知。
20年8月获维新力特资本领投的A轮投资,具体金额未知。
20年12月获高瓴资本领投的C轮1.4亿人民币投资。
EMQ创始人李枫13年起就开始参与开源项目,早年任职华为,在EMQ 项目之前还曾成功创办过一家企业服务软件公司,拥有多年的企业运营经验,是一位商业开源的忠实信徒。
EMQ长期以来一直将开源,实时性和高并发作为自己的核心卖点,围绕自研MQTT消息中间件对IOT场景和边云结合方向进行探索。演化出多个服务端和边缘端产品。在关注国内市场的同时,同样关注海外市场,拥有众多海内外用户。
快立方Qcubic - QFLOW
2013年成立
2021年1月,获东华软件的750万人民币战略融资
柏睿数据BorayData - Rapids StreamDB
2014年创立,最早以内存数据库作为主打产品,基于经典的MPP架构。
2015年柏睿数据获得蓝驰创投近千万元PreA轮投资。
2016年获得数千万A轮融资,由信中利领投。
2017年5月,柏睿数据获得中科院国科嘉和基金投资的千万级美元B轮融资。
2018年获得东方嘉富、盛世泰诺等亿元人民B+轮投资。
2020年获海通证券与盛石资本2亿元人民C轮投资。
博睿数据的创始人刘睿民确实是数据库领域的老兵,师从著名的数据库学者,图灵奖创始人Jim Grey,先后在多家企业担任技术骨干。参考其个人访谈,可以看出其对于数据库技术的热爱和对前沿技术的关注。
柏睿数据是比较早提出流数据库概念的公司,主笔参与制定了相关ISO标准(虽然最终这一标准被取消)。由于博睿数据对外披露的Rapids StreamDB信息披露甚少,也没有对系统进行开源,博睿数据对于流数据库的定义与上文提到的到底有多少重合,还不好说。
奇点无限SingularityData
奇点无限大约创立于21年初或20年底,
21年初,获数百万美元种子轮投资。
21年8月获云启资本的种子轮近千万美元投资。
奇点无限的CEO吴英骏博士毕业于新国立,先后在IBM的数据库团队和AWS的RedShift团队工作。是Flink的早期贡献者。
联合创始人张焕晨本科就读于UW-Madison,师从著名存储大拿Remzi Arpaci-Dusseau。博士毕业于CMU,师从数据库科学家Dave Andersen和AndyPavlo。目前在清华姚班担任助理讲师。2021年5月获数据库领域的大奖Jim Gray Dissertation奖。
奇点无限是近期市场上最热的基础架构创业公司之一,在种子轮已估值达到上亿美金,是许多投资人眼中的香饽饽。目前他们的系统还在紧锣密鼓的开发,团队扩张也在进行中。不少基础架构领域的年轻人都以加入这家公司作为目标。
国外
Confluent - ksqlDB
Confluent建立于2014年。
14年5月获Benchmark领投的A轮690万美元投资。
15年7月获Index Ventures领投的B轮2400万美元投资。
17年3月获Sequoia Capital领投的C轮5000万美元投资。
19年1月获Sequoia Capital领投的D轮1.25亿美元投资。
20年4月获Coatue领投的E轮2.5亿美元投资。
21年6月以91亿美元的市值在纳斯达克证券交易所上市,首个交易日跳涨超过20%。
Confluent是在Kafka的基础上创建的公司,创始人团队来自Linkedin,主要是Jay Kreps、Neha Narkhede和饶军三人。Kafka作为中间件在现代大数据格局中扮演了重要的角色,提供开源和商业版两个版本,几乎是所有互联网公司软件架构中必备的组件。Confluent的价值也因为Kafka的普及而迅速提升。而后Confluent基于Kafka研发了许多外围组件出售,其中就包括基于Kafka出来的流式数据形式演化出来的事件流数据库KsqlDB。
Confluent无疑是一家成功的公司,从初创企业到上市一步一个脚印,同时也给其他创业公司释放一个信息,在大数据时代,选好一个角色的重要性。
Materialize - Materialize
2019年融资由Lightspeed领投完成800万美元的A轮融资。
2020年融资由Lightspeed领投完成3200万美元的B轮融资。
Materialize拥有强大的团队,包括前Cockroach Labs的首席执行官Arjun Narayan和首席科学家Frank McSherry。他们希望用自己的系统将每个公司的软件在不进行任何额外技术培训的前提下转换为高实时性软件。标准SQL的支持是他们的主打特性之一。Materialize的原型Naiad,是一些流数据库从业者视为行业开拓者的系统。
Rockset - Rockset
2016年种子轮获300万美元投资
2018年获Sequoia Capital领投的185万美元的A轮融资。
2020年获Sequoia Capital领投的4000万美元的B轮融资。
CEO Venkat Venkataramani毕业于Wisconsin-Madison,02年起在Oracle工作5年,然后07到Facebook,工作了8年,在创办Rockset之前是Facebook负责在线数据平台的工程总监。16年创办RockSet。
CTO Dhruba Borthakur,毕业自Wisconsin-Madison,先后工作于IBM、Veritas,06年加入Yahoo,是HDFS创始人之一,也是重要的HBase contributor。08年起在Facebook干了8年,是RocksDB的创始人。
Rockset踩在了云原生的风口上,提出了OPAP的概念,拥有极强的团队组成,是实时数据库这一方向不可忽视的力量。
期待的发展方向
-
清晰产品定位,制定比较统一的产品标准。现有对流数据的应用一般是不需要长期保存数据的,一般会a. 只保留数据计算的结果,b. dump数据到HDFS等冷存平台。流数据库的存储能力在这些场景下显得不太必要。真正需要直接存储流数据的场景不一定有很多。
-
做好流处理数据一致性方面的设计,可以在延时和一致性之间提供选择的余地。
-
做好模块化的设计,提供消息队列能力,存储的松解藕能力的支持。
-
做好性能和scalability的平衡。是顺应计算存储分离大潮,保持scalability,换取低延时,还是放弃一部分延展性,追求极致的性能。
-
Materialized View本身的分布式化的相关技术似乎不多,如何做还是个未知数。
-
解决或者进一步削减Materialize Views这一技术带来的潜在问题,额外的大量内存/硬盘资源消耗。
流数据库&时序数据库&OLAP
流数据库&时序数据库的对比
流数据库和时序数据库的对比可能是对流数据库感兴趣的人经常会遇到的问题,这两种系统在一定程度上是有重叠的,他们都重点关注请求的低延时。但是分别做出了不同的tradeoff。

时序数据库本质上是一种AP能力的特化优化,放弃了一部分比如Join操作的性能来获取其他操作上的性能。其在生产场景中的写入模式更类似于TP,读取模式类似AP。时序数据库针在基本没有消耗更多系统资源的条件下,对这种操作模式提供特定优化,形成一个类似窄列数据库的系统模型。涛思数据的TDengine甚至专门针对IoT这一单一场景做系统设计,依靠反木桶原理创造出了美好的性能指标。
目前流数据库的设计基本是可以覆盖时序数据库中的需求的,但是从存储和系统优化的角度来说,大概率做不到TSDB这种极致优化。如果希望提供一站式服务,必定需要牺牲极致的性能。流数据库是在尽量保证计算能力的完备性条件下,使用资源换性能的方式给出了自己的性能提升。
流数据库&OLAP的对比
流数据库能不能取代OLAP,用流式的能力完成批式运算,可能也是很多人会感兴趣的话题。目前来看似乎还存在一些GAP,一个是OLAP毕竟很多时候是在离线在batch运算,可以做很多单独的性能优化,但是streaming database未必可以做到同等的优化程度。再有就是批式计算还是有一些场景/Corner Case是流式处理无法覆盖或者很难处理的。短期内我们可能看不到流数据库能完全cover OLAP的局面,但是长期来看流数据库这一数据模型应该是有这个潜力的。
结论
流数据库作为一个新兴的数据模型,从功能性角度讲,具有较大的潜力,理论上可以以相对优雅的性能,处理几乎所有的请求和分析模式。从性能角度讲,目标是实现实时或近实时的请求处理。对应的,流数据库为自身引入了一定的系统复杂度和较高的额外资源开销。
流数据库作为一个新兴的商业软件,在市场规模上,顺应流数据和时序性需求的发展,会有不错的潜力。在市场竞争中,还处于比较早期的时间点,参与竞争的企业较少。目前真正使用流数据库的企业不多,企业需要在寻找合适的用户上多做投入,甚至自己培养用户习惯。在不断扩展市场需求的同时,提高自身多能性,实时性,易用性,是流数据库未来的出路。
https://calcite.apache.org/docs/stream.html#references ↩︎ ↩︎
https://researcher.watson.ibm.com/researcher/view_group.php?id=2531 ↩︎
https://conferences.computer.org/icde/2020/pdfs/ICDE2020-5acyuqhpJ6L9P042wmjY1p/290300b591/290300b591.pdf ↩︎
https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf ↩︎
https://wiki.postgresql.org/wiki/Incremental_View_Maintenance ↩︎
http://www.jouypub.com/2019/aba9afaf67ef3851b7cf3ddd6c6e8ef1/ ↩︎
https://wiki.postgresql.org/images/a/ad/South_Bay_PG_Meetup_2016-03-08_PipelineDB.pdf ↩︎
https://dspace.mit.edu/bitstream/handle/1721.1/130767/1252061486-MIT.pdf?sequence=1&isAllowed=y ↩︎
https://blog.acolyer.org/2018/10/29/noria-dynamic-partially-stateful-data-flow-for-high-performance-web-applications/ ↩︎
https://www.notamonadtutorial.com/interview-with-norias-creator-a-promising-dataflow-database-implemented-in-rust/ ↩︎
https://www.confluent.io/blog/intro-to-ksqldb-sql-database-streaming/ ↩︎
https://wemp.app/posts/4d7b00ea-247b-457a-97cf-89243cc78813 ↩︎
https://www.emqx.cn/blog/hstreamdb-is-now-officially-open-source ↩︎
https://www.marketsandmarkets.com/PressReleases/cloud-database-as-a-service-dbaas.asp ↩︎
https://www.marketsandmarkets.com/Market-Reports/data-warehouse-as-a-service-market-191544663.html ↩︎
https://www.marketsandmarkets.com/Market-Reports/streaming-analytics-market-64196229.html ↩︎
https://www.marketsandmarkets.com/Market-Reports/cloud-based-business-analytics-market-959.html ↩︎
